Hoje falarei sobre um banco de dados ótimo para trabalhar com aplicações web ou mobile com Javascript, ele é o PouchDB.
Sobre o banco de dados
De acordo com a documentação, o PouchDB é um in-browser database, ou seja, ele utiliza a persistência do navegador, utilizando o IndexedDB por padrão, porém é possível alterar o plugin de persistência para gravar em WebSQL ou localstorage.
Ele é um banco NoSQL, feito totalmente em Javascript, e possui sincronização. Sim, é isso mesmo, você pode definir um banco remoto e voilà, as informações estão replicando.
Se desejar rodar fora do browser, como por exemplo, uma aplicação ElectronJS ou React-Native, o PouchDB utiliza o LevelDB como servidor de dados.
Resumidamente, o PouchDB é apenas uma camada de abstração, que permite desenvolver aplicações cross-browser ou cross-platform com a mesma chamada de API.
Disponível em: https://pouchdb.com/adapters.html
Limitações dos browsers
Nem tudo na vida são flores, e ao se trabalhar com dados no browser, temos que cuidar com o que deve ser salvo local, pois os navegadores limitam o uso de disco, logo, não podemos replicar um banco de um ERP completo. Devemos assim mapear quais recursos são imprescindíveis offline, além de ter alguma rotina de expurgo.
Veja abaixo algumas tabelas disponibilizado pelo site html5rocks:
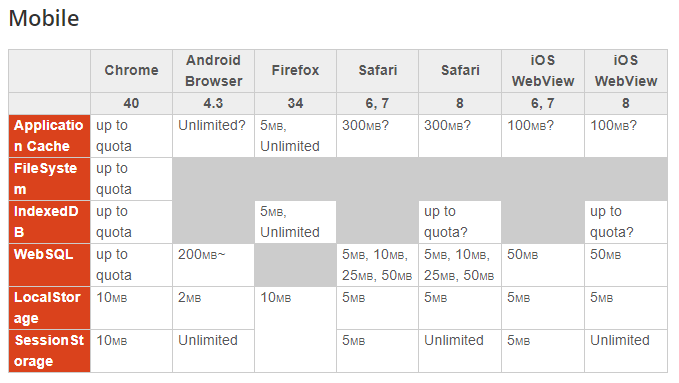
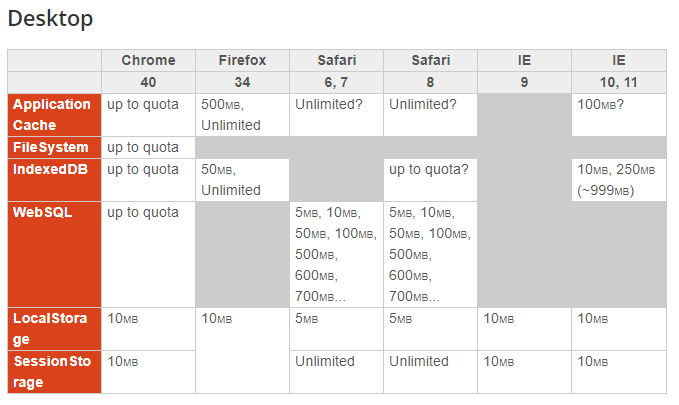
Disponível em: https://www.html5rocks.com/en/tutorials/offline/quota-research/
PWA e Service Worker
O PouchDB não descarta os conceitos do PWA com Service Worker, ele na verdade é um complemento que facilita o acesso aos dados.
É possível capturar o dado primeiramente no PouchDB e enfileirar a requisição, utilizando o Service Worker. Porém, o Pouch oferece o recurso de replicação de dados automático, podendo trabalhar com um ar de estar totalmente offline. Claro que é preciso tratar os dados no servidor da nuvem, pois ele estará recebendo cargas gigantes de dados a todo momento.
Quais diferenciais posso oferecer?
Ao utilizar replicação com banco de dados remoto, é possível utilizar um plugin de sincronização entre terminais com WebRTC, ou seja, distribuímos o consumo dos dados com terminais próximos, em uma conexão P2P. Desta forma, o servidor não precisa escalar de forma absurda em memória ram e cpu, a carga de trabalho acaba sendo dividido com o cliente.
Exemplos de código
Este exemplo mostra o uso básico em um projeto React, o mesmo pode ser aplicado com Angular, View, React-Native ou mesmo Javascript Vanilla.
O intuito do exemplo não é ensinar o uso do React, logo é feito da forma mais simples possível, sem a utilização de controle de estado com Redux, entre outras coisas.
Para iniciar o projeto utilize o comando:
yarn create react-app react-pouch
Um projeto com React foi gerado, agora para adicionar a dependência do PouchDB com o comando:
yarn add pouchdb-browser
Apague o conteúdo do App.js e vamos seguir no passo a passo:

Importamos a dependência do Pouch, e em seguida vamos criar o componente, instanciando o banco e construindo o estado do componente.
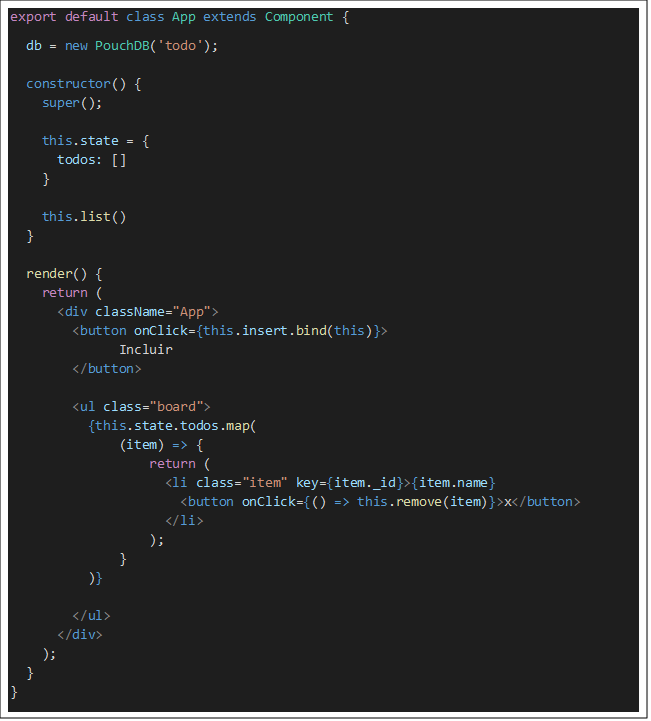
Até o momento, todo código é para o exibir o html em si. Abaixo vamos implementar os métodos list(), insert() e remove().
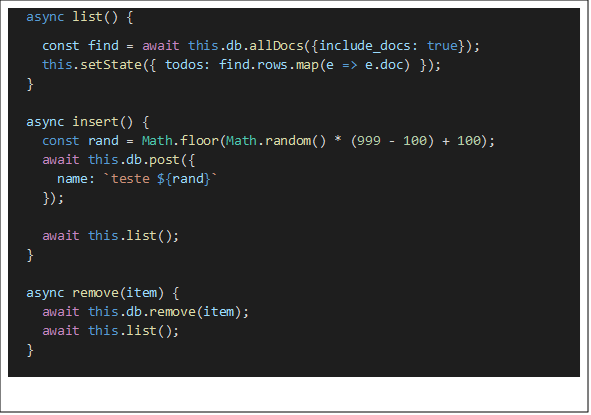
O comando list traz todos documentos salvos, foi feito um map para trazer o objeto direto, sem os complementos dos dados para trabalhar com HATEOS, como paginação dentre outras informações.
O comando insert faz um post de um nome randômico, por padrão os documentos salvos com POST geram um _id único. Caso fosse passar o _id, poderia efetuar a chamada PUT.
O comando remove deleta o documento, como pode ser visto, a chamada é muito limpa.
Para fazer a replicação dos dados, é preciso ter um servidor CouchDB, PouchDB ou Cloudant rodando.
É possível escutar as alterações de dados, para quando se trabalha com replicação, para fazer alguma atualização da página.
Vamos então remover as chamadas “await this.list” do remove e do insert, e no construtor, adicionaremos a seguinte linha:

Pronto, agora temos um listener que ao receber uma alteração no banco, atualiza a listagem do componente.
Agora falta apenas sincronizar estes dados, para isto vamos ter 3 opções. Você pode utilizar os métodos:
- replicate.to: replica os dados do cliente para o servidor remoto
- replicate.from: busca alterações no servidor remoto
- replicate.sync: manter a sincronização completa de ida e volta com servidor remoto
Para isso, vamos inserir a seguinte linha no construtor da nossa classe:

Este código completo pode ser baixado no link: https://github.com/ramonnteixeira/react-pouch
Outros exemplos podem ser visto em: https://github.com/ibm-watson-data-lab/shopping-list-vanillajs-pouchdb
E o servidor?
Acredito que você deva estar se perguntando como gerenciar um banco de dados para suportar essa sincronização.
Eu poderia escrever que você devesse criar um servidor e instalar o CouchDB, ou mesmo um PouchDB server. Porém essa alternativa demandaria um alto conhecimento em tipos de máquina cloud, monitoramento e etc.
Por isso indico o Cloudant, um banco de dados mantido pela Apache, disponibilizado pela IBM.
Disponível em: https://www.ibm.com/cloud/cloudant
Mostrarei como podemos criar e acessar um banco Cloudant. Acessando o console da IBM cloud, criaremos um banco de dados Cloudant, o custo do banco é exibido durante a criação, conforme as imagens abaixo:

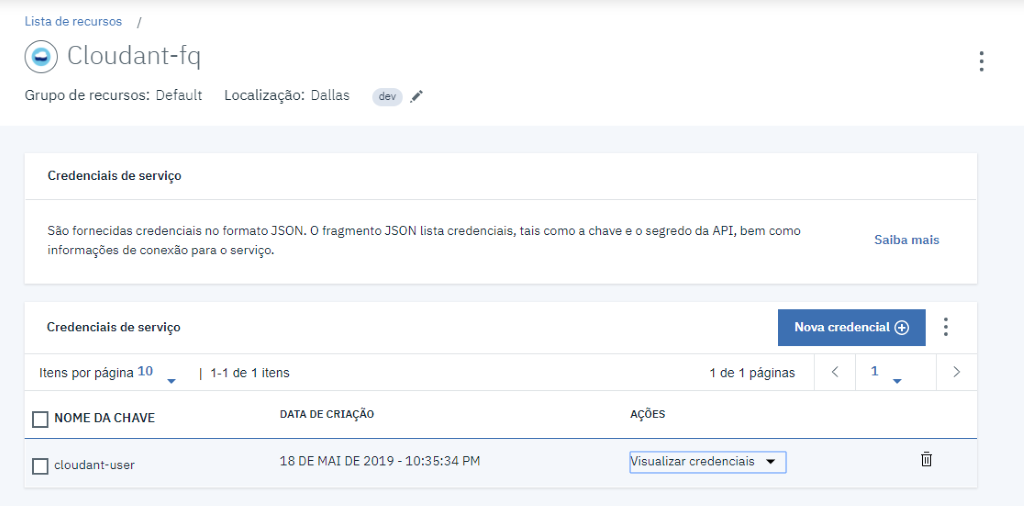
Após subir a instância, vamos criar uma credencial de acesso ao banco.
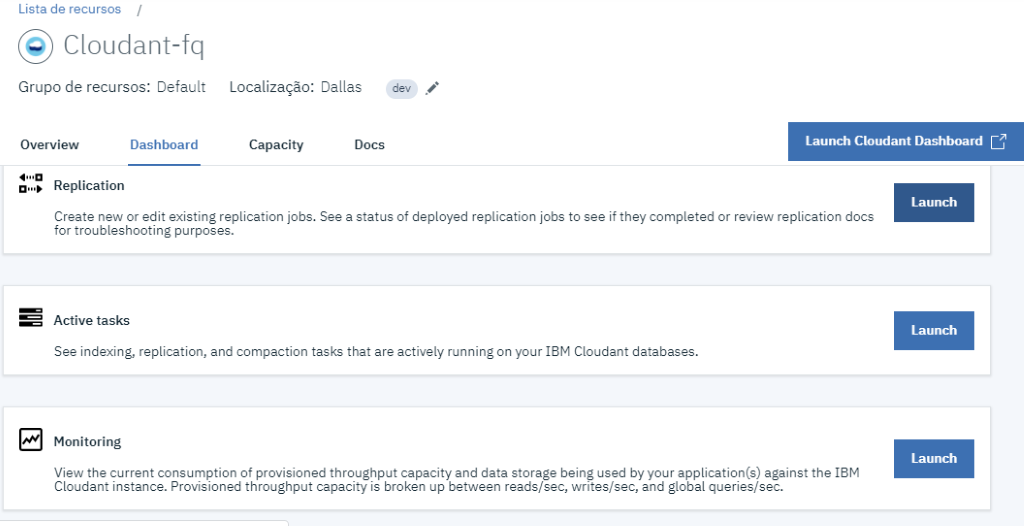
Agora vamos acessar o painel do banco, indo na aba dashboard e clicando no botão Lauch.
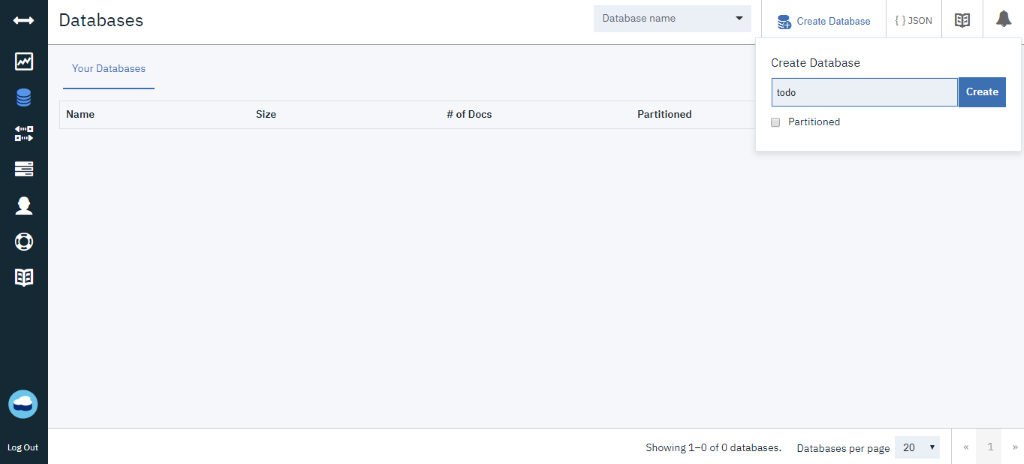
Após entrar no banco de dados, vamos criar um database.
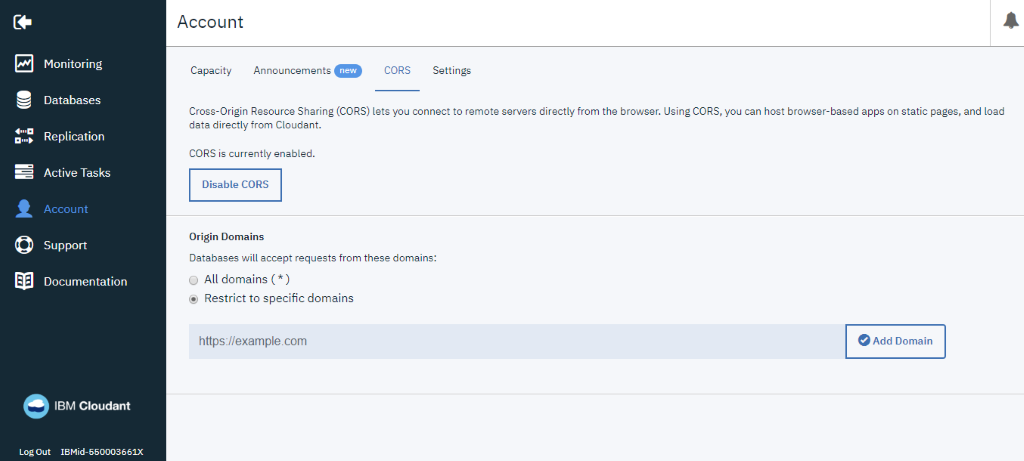
Agora no menu lateral, vamos acessar os dados de conta para liberar o acesso de CORS para todos domínios (*). Para saber mais sobre CORS, acesse https://developer.mozilla.org/pt-BR/docs/Web/HTTP/Controle_Acesso_CORS.
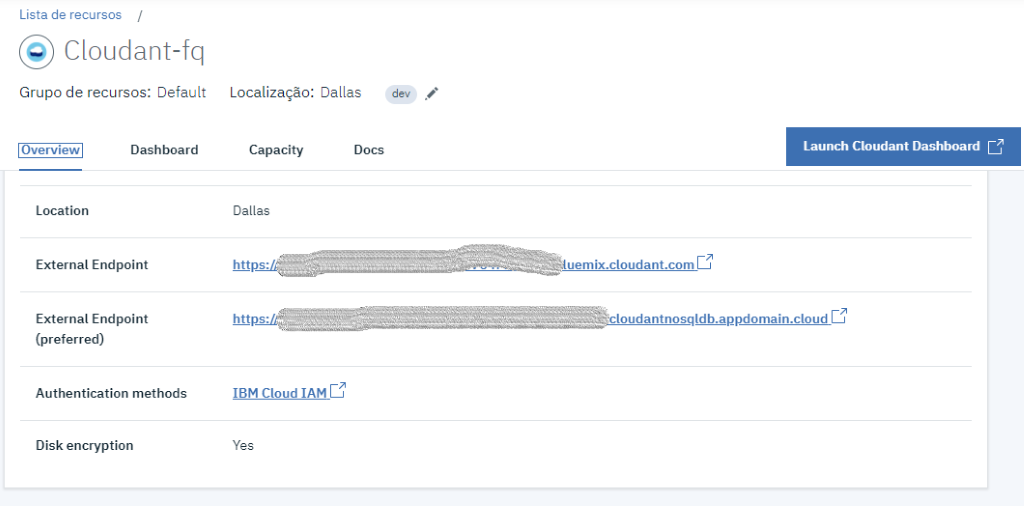
Vamos pegar o endpoint de acesso do banco na tela de dashboard, alteramos o link na aplicação react e pronto, os dados estão sincronizando.
Desafios a serem enfrentados
Claro que ao resolver grandes problemas, surgem desafios para serem superados, e no caso da stack apresentada surgem alguns pontos que devem ser vistos com atenção, sendo eles:
- Atenção as limitações dos browsers
- Pensar em fazer ETL de dados na nuvem, para consolidar informações
- Replicação com tenâncias para garantir segurança
- Criptografia dos dados
Com tudo isso para ser explorado, espero que esse artigo tenha te ajudado a começar seus estudos!
Sobre o autor
Ramon Teixeira é formado em Sistemas de Informação pela UNISUL, atualmente esta finalizando a especialização em Arquitetura de Software. Integrante da equipe IT Services da DB1 Global Software, atua como desenvolvedor Java. Se interessa por tecnologias e técnicas que impactam na arquitetura de sistemas e na quebra de paradigmas.